Qwen-VL 系列模型技术报告整理
概述
Qwen-VL 系列是通义千问团队推出的多模态大语言模型,从 Qwen-VL 到 Qwen3-VL 经历了多次重大升级。本文整理了各版本的核心架构与技术要点。
Qwen-VL
Qwen-VL 以 Qwen-7B Base 为主干模型,通过引入视觉感知器(Visual Receptor)来增强视觉特征的感知能力。主要包括三个部分:
- 模态编码器(Modality Encoder):视觉编码器(Visual Encoder),用于编码图片视觉特征
- 输入投影层(Input Projector):位置感知的适配器(Position-aware Adapter)
- LLM 主干网络(LLM Backbone):Qwen-7B Base 模型
视觉编码器
Qwen-VL 的视觉编码器使用 ViT 架构(Vision Transformer),初始化参数来自 OpenCLIP 预训练的 ViT-bigG 模型。
ViT-bigG 基于 CLIP 框架训练,通过对比学习(Contrastive Learning)学习视觉和文本的表征。对于一个 Batch 的数据,以原始图文 pair 为正例,Batch 内与其他样本组成负例 pair,通过最大化正例相似度、最小化负例相似度来训练。
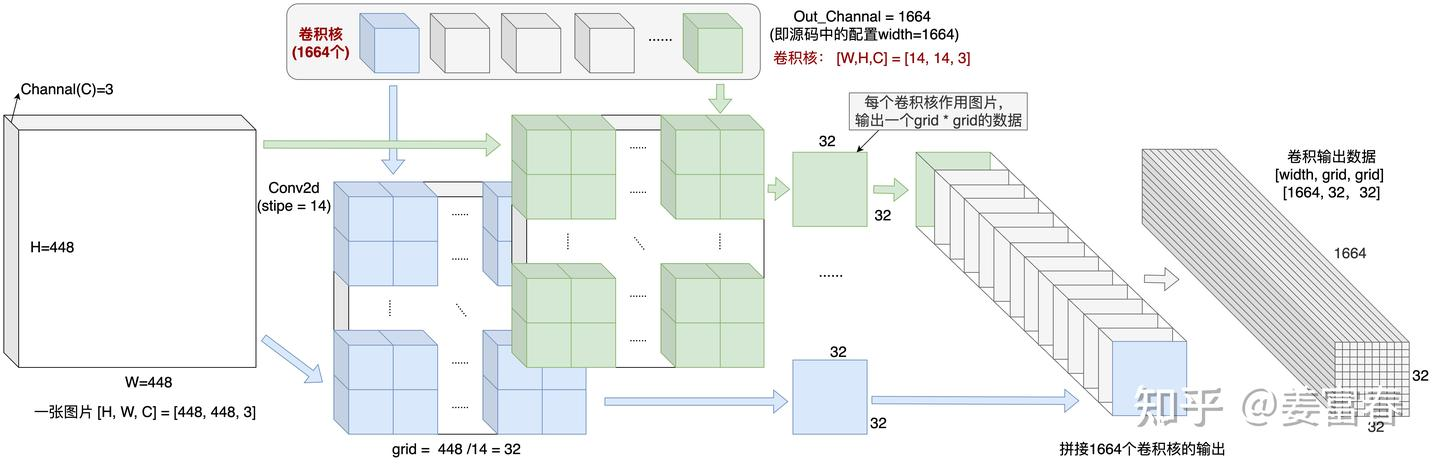
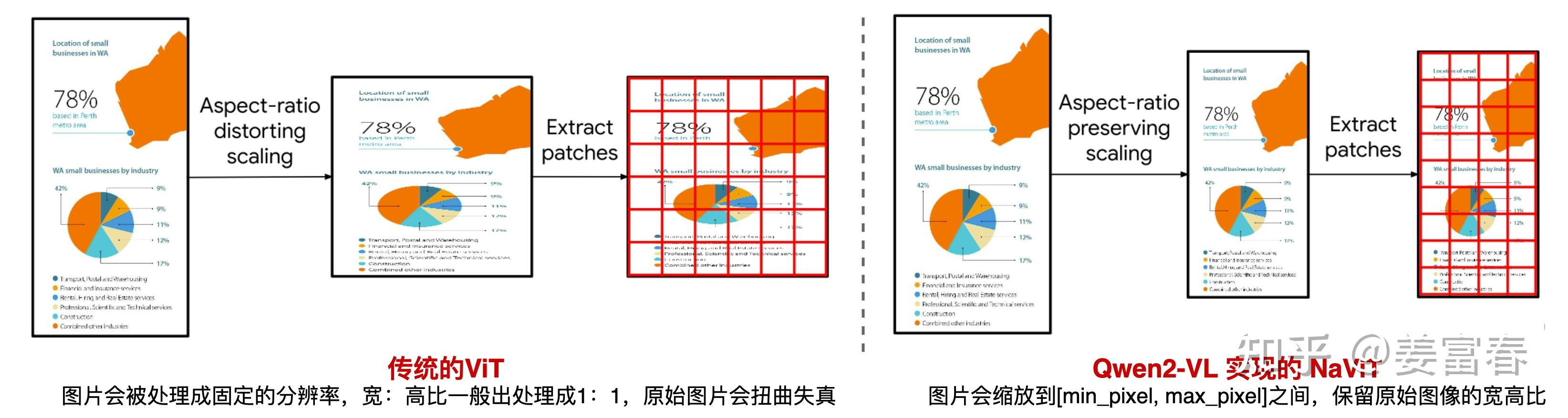
在标准 ViT 实现中,输入图片会先被调整成 1:1 的正方形,然后分割成固定的图像块。Qwen-VL 可接受的图像分辨率为 448×448,参数设置:
patch_size: 14width: 1664(每个 Patch 输出特征的维度)
输入投影层
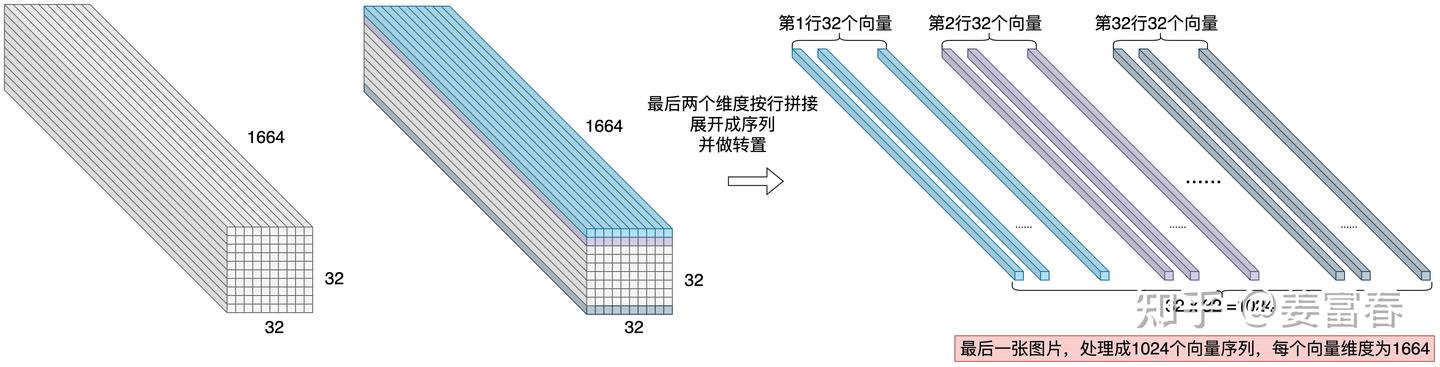
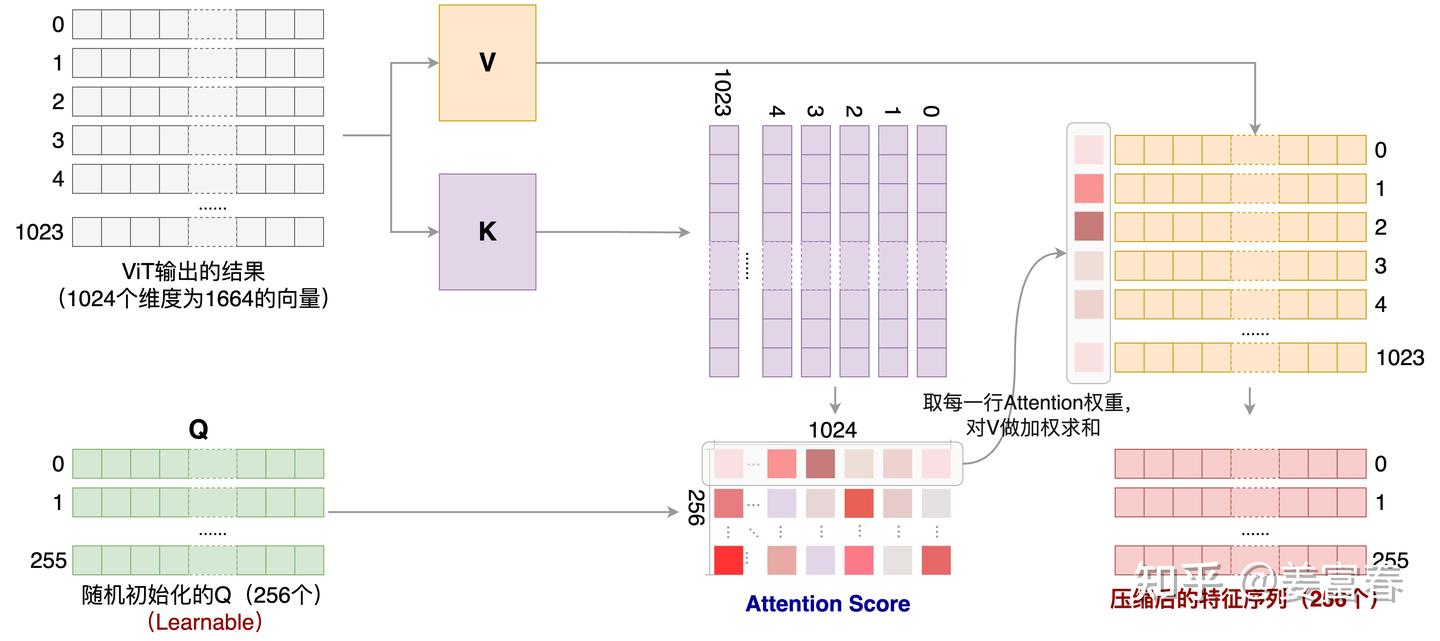
经过 ViT 处理后,448×448 的图像生成维度为 1664、长度为 1024 的序列。为压缩视觉 token 输入长度,Qwen-VL 引入了一个随机初始化的单层 Cross-Attention 模块作为 Adapter:
- 使用一组可学习的 query 向量
- ViT 的图像特征作为 Key 向量
- 通过 Cross-Attention 将视觉特征序列压缩到固定的 256 长度
同时将二维绝对位置编码(三角位置编码)整合到 Cross-Attention 的 Q 和 K 中,减少压缩过程中的位置信息丢失。
输入输出
为区分图片和文本输入,图像特征的开始和结束用 <img> 和 </img> 特殊 token 包裹,明确标识图像特征的起止位置。

训练过程
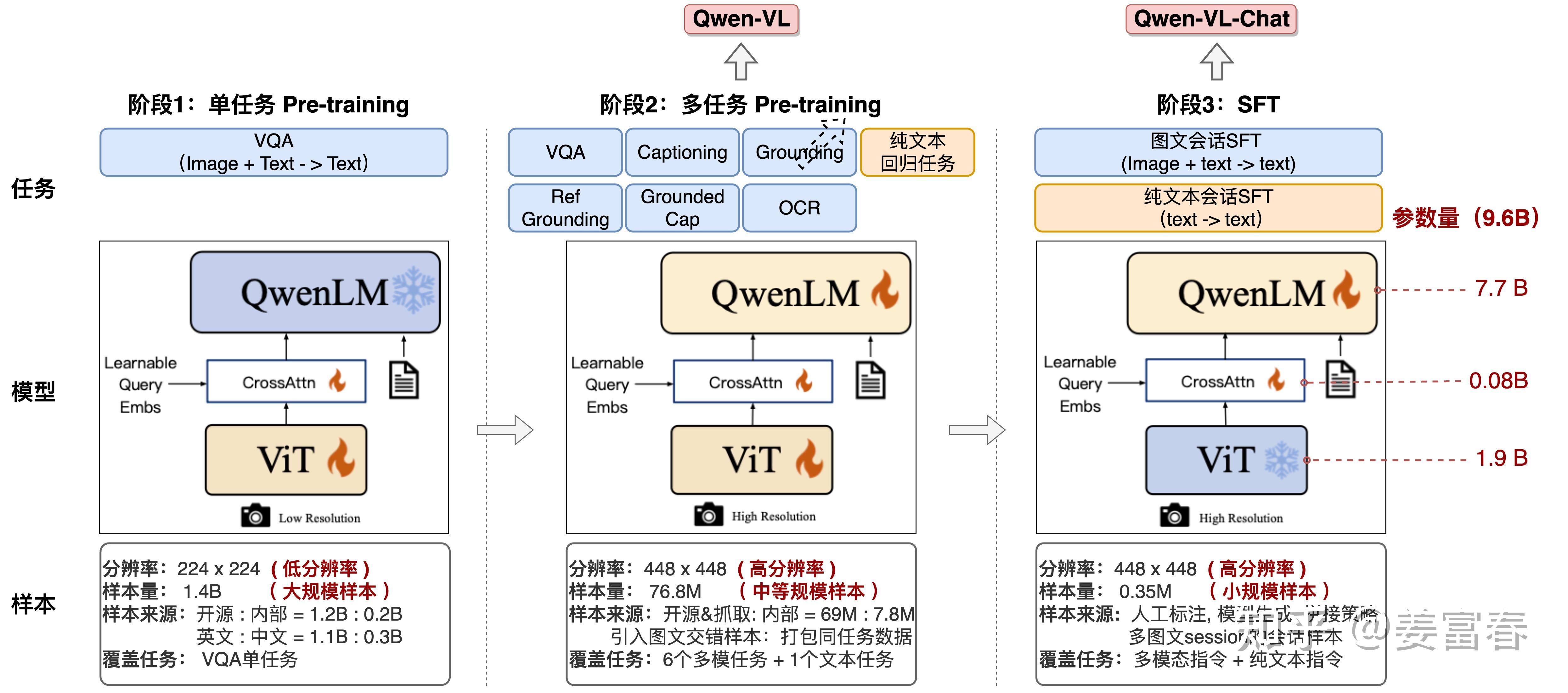
分为 3 个阶段:
第一阶段:单任务大规模预训练(Pre-training)
- 使用大量网络抓取和内部图文 pair 数据,训练数据 1.4B(英文 77.3%,中文 22.7%)
- 图片统一处理成 448×448
- LLM 参数冻结,ViT 和 Cross-Attention 层参数激活更新
- 目标:训练视觉模态对齐语言模型的能力
第二阶段:多任务预训练(Multi-task Pre-training)
- 更高分辨率、更高质量数据,引入图文混排
- 7 个任务:6 个 Vision 任务(Captioning、VQA、Grounding 等)+ 1 个文本生成任务
- 全参数激活
- 数据:多模态数据 69M + 文本数据 7.8M
- 产出:Qwen-VL Base 模型
第三阶段:指令微调(SFT)
- 提升指令遵循能力和对话能力
- 通过人工标注、模型生成和策略拼接构造多轮会话数据
- 指令集数据 350K
Qwen2-VL
Qwen2-VL 对 Adapter 做了简化处理,使用简单的线性变换层替代 Cross-Attention。系列模型针对 Vision Encoder 采用了相同 size 的模型结构。

主要升级点
| 特性 | Qwen-VL | Qwen2-VL |
|---|---|---|
| 分辨率 | 单一分辨率 448×448 | 原生动态分辨率(任意分辨率) |
| ViT 位置编码 | 2D 绝对位置编码 | 2D-RoPE 相对位置编码 |
| LLM 位置编码 | 1D | 3D RoPE(M-RoPE) |
| 多模态数据 | 仅图片 | 统一图片和视频 |
| 训练数据 | 1.4B | 1.4T(提升 3 个量级) |
动态分辨率
原生动态分辨率方法保留原始图片的宽高比,将图片 resize 到适当大小,再做 Patch 处理,将每个图片处理成变长的 Vision token 序列。
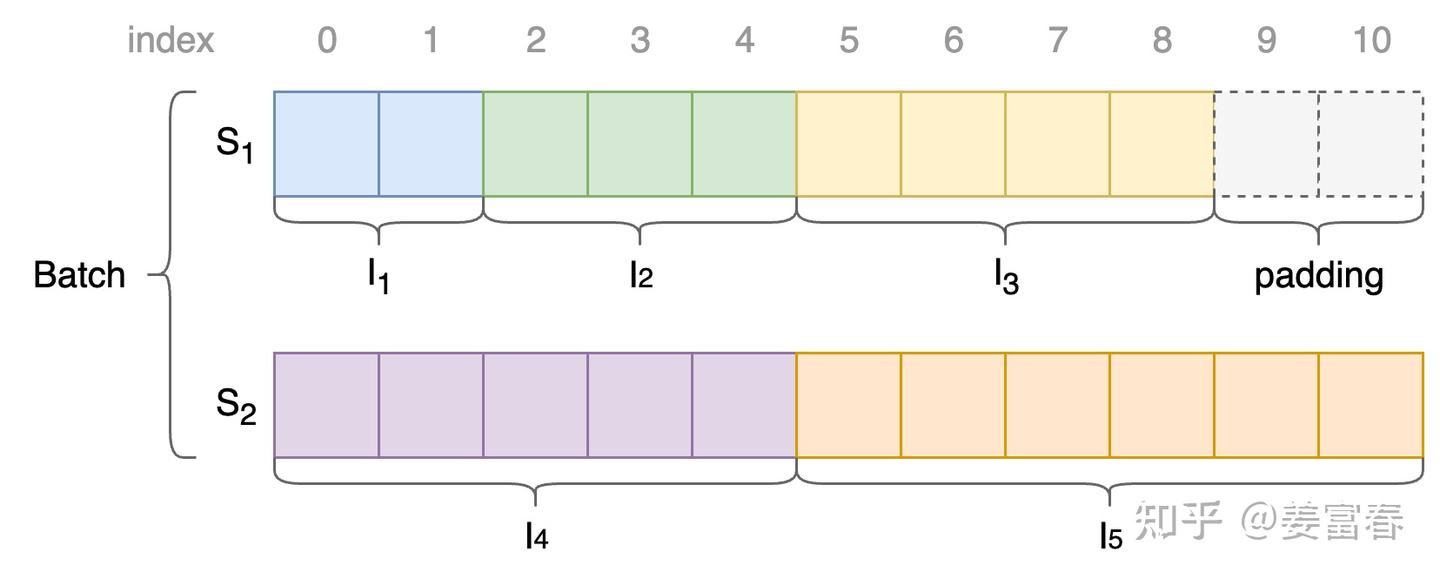
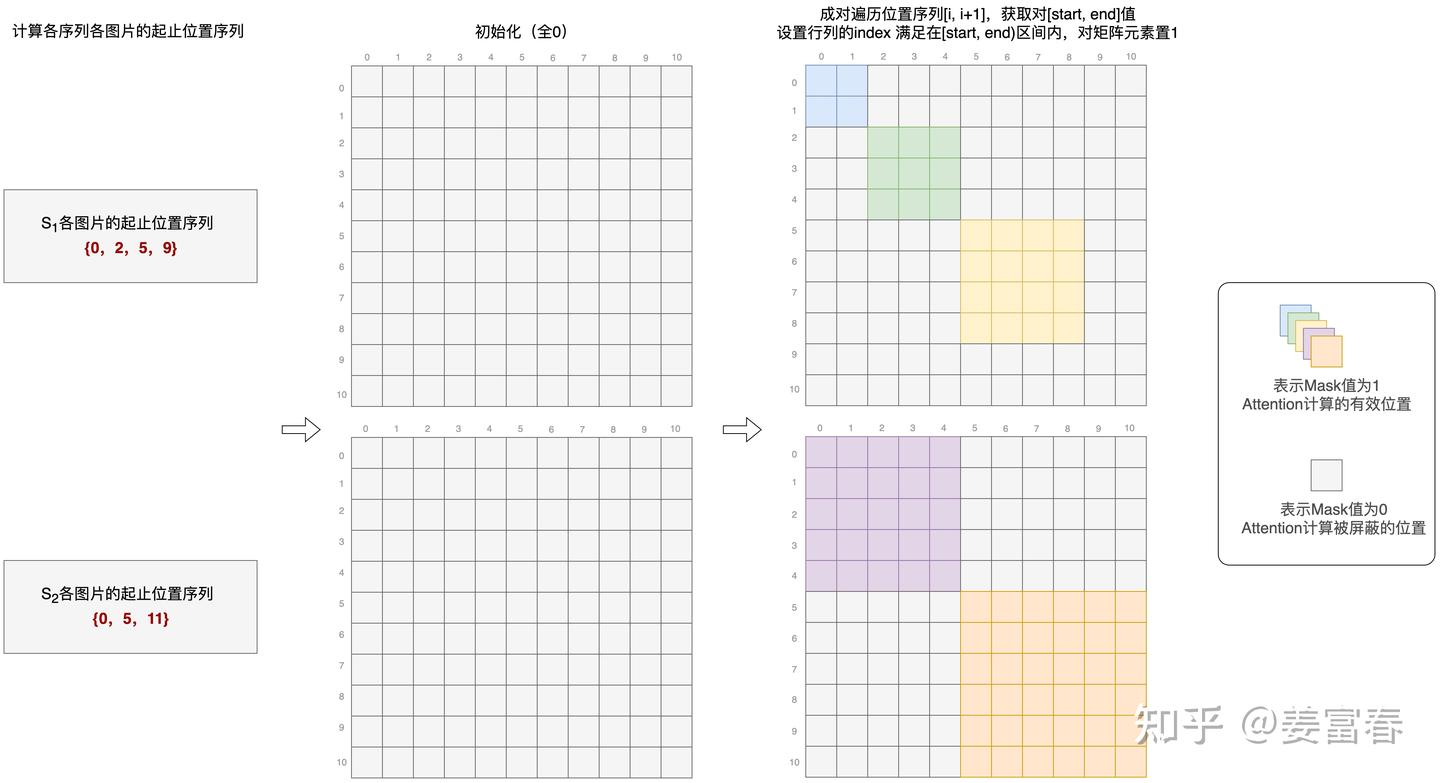
核心方法采用 NaViT 的 Patch n’ Pack 技术,把不同图像的多个 patch 打包到一个序列:
- 将多张图片进行 Pack,放到序列中
- 通过设置 Attention Mask 保证同 Sequence 中各图片计算隔离
ViT 引入 2D-RoPE 位置编码
将输入向量分为两半,一半施加 x 的一维 RoPE,一半施加 y 的一维 RoPE。
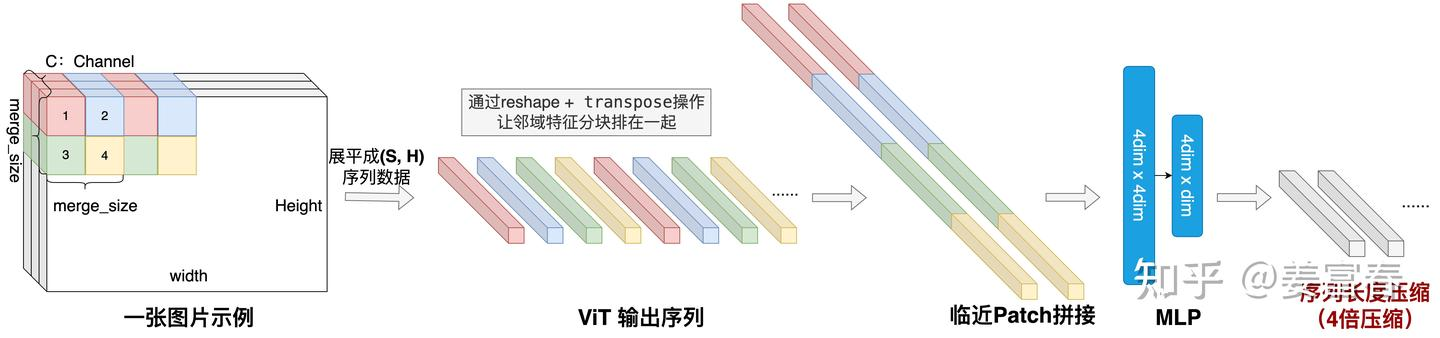
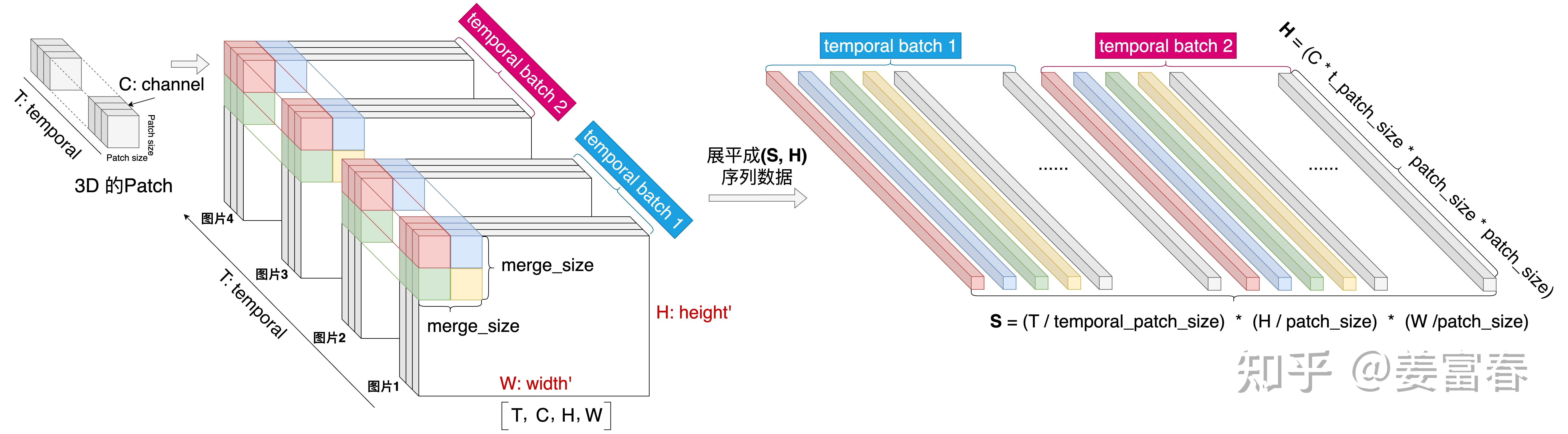
输入投影层:压缩 Vision Token + MLP Adapter
对空间位置临近的 patch 特征做拼接,再经过 2 层 MLP 线性变换,将原来长度为 n 的序列压缩到 n/4,最终输入给 LLM 模型。
M-RoPE(Multimodal Rotary Position Embedding)
M-RoPE 将位置编码从 1 维扩展到 3 维(时序、高、宽),能清晰刻画视频模态数据的时空位置信息:
- 文本:三个维度的值保持一致,退化成 1D-RoPE
- 图像:只有宽高两个维度,时序维度 T 始终保持固定
具体做法:对维度为 d 的输入向量分成三份,分别用 x、y、z 的一维 RoPE 矩阵处理,再拼接。

统一的图像和视频理解框架
- 视频处理:以每秒两帧的速率采样,可采样偶数个帧序列。长视频通过动态调整每帧分辨率,将视频总 token 限制在 16K 以内
- 图像处理:对图像做复制操作,使单一图片变成时序为 2 的帧序列
模型训练
采用与 Qwen-VL 一致的三阶段训练方式,但数据规模大幅提升——从 1.4B 直接翻了 3 个量级达到 1.4T。
Qwen2.5-VL
主要升级点
提升时间和空间的感知能力
- 空间感知能力:Grounding 任务中不再进行坐标归一化,而是使用实际像素点表示坐标,使模型学习到图像的真实尺寸信息
- 时间感知能力:时间维度的位置 ID 采用绝对位置编码;引入动态帧技术,每秒随机动态采集帧序列,使模型能通过不同时间 ID 的间隔学习时间节奏
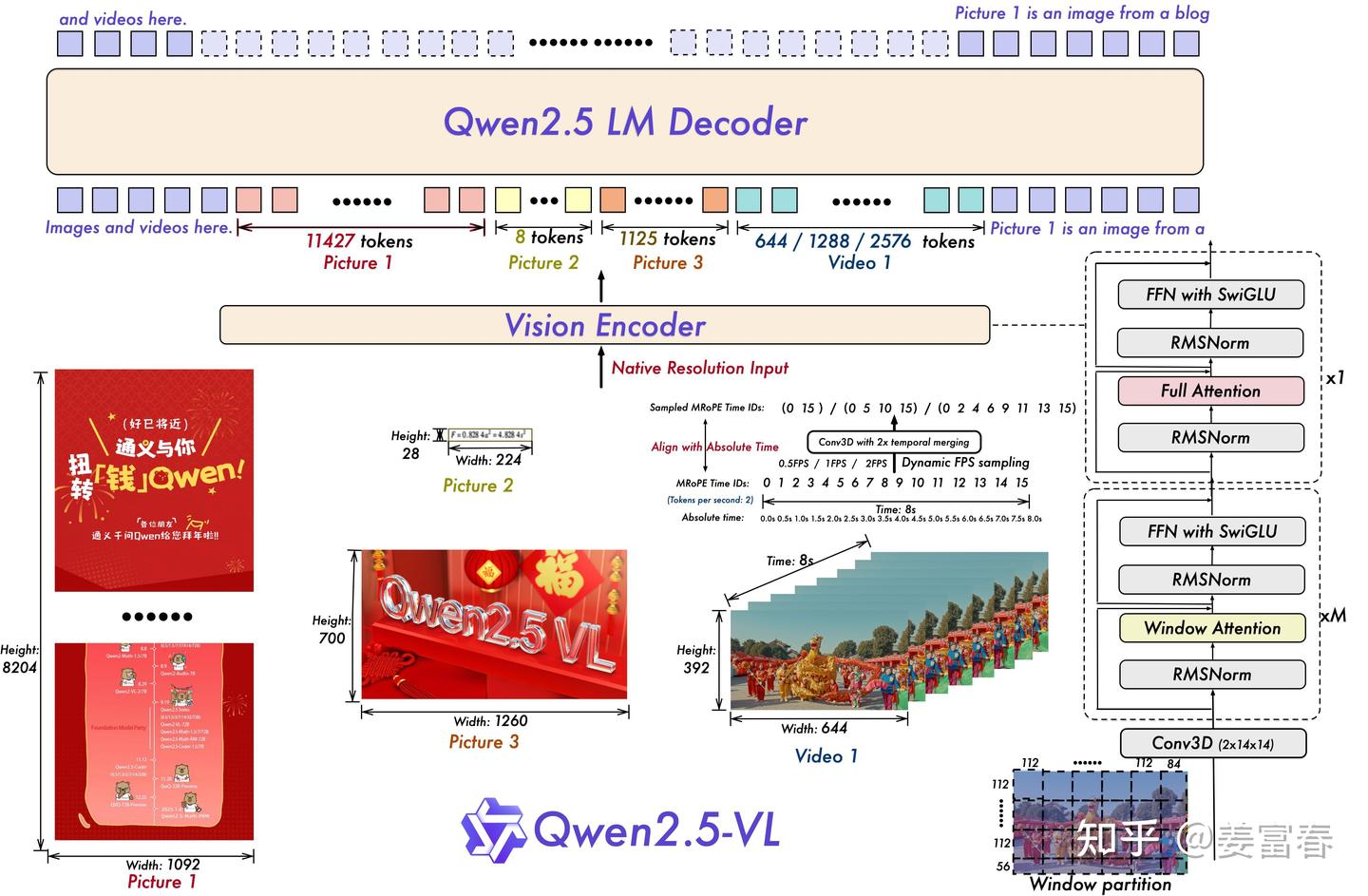
更简洁高效的视觉编码器
- 从头训练对原生动态分辨率的 ViT
- 引入窗口注意力机制,有效减少 ViT 端的计算负担:
- 只有 4 层是全注意力层,其余层使用窗口注意力
- 最大窗口大小为 8×8
- 小于 8×8 的区域保持原始尺度,确保原生分辨率
- 简化整体网络结构,ViT 架构采用 RMSNorm 和 SwiGLU 结构
Qwen3-VL
主要升级点
- Interleaved-MRoPE:频谱均衡,修复长视频位置偏差
- DeepStack:ViT 多层特征注入 LLM 前 3 层,无额外序列长度开销
- 文本 Timestamp Token:替代绝对时间编码,实现精确时序定位
系列演进总结
| 版本 | 视觉编码器 | 投影层 | 位置编码 | 分辨率策略 | 数据规模 |
|---|---|---|---|---|---|
| Qwen-VL | ViT-bigG (OpenCLIP) | Cross-Attention (→256) | 2D 绝对 + 1D | 固定 448×448 | 1.4B |
| Qwen2-VL | 同结构 ViT | MLP (→n/4) | 2D-RoPE + M-RoPE | 原生动态 | 1.4T |
| Qwen2.5-VL | 窗口注意力 ViT | MLP | 绝对时间编码 + 动态帧 | 原生动态 | - |
| Qwen3-VL | DeepStack ViT | - | Interleaved-MRoPE | 原生动态 | - |